Accessing pandas DataFrame using SQL-like select statements
2018-11-12
Recently I was writing the following code:
processing_frame = \
sl_results[sl_results.c == coi][["subscript", "kappa"]].rename(
columns={"kappa": "value"})
Another piece of code that might look familiar to the habituated pandas user is:
my_frame[(my_frame.col1 == a) & (my_frame.col2 == b) & (my_frame.col3 < c)]
Typing this kind of stuff is annoying, and it triggers me every time I write something like this. Ideally, this would look more like:
my_frame[col1 == a and col2 == b and col3 < c]
which is not supported by the python syntax. What can be done, however, is the following:
Select("subscript, kappa as value").Where(f"c == {coi}")(sl_results)
In this post, I'll walk you through the code that makes the upper statement possible. For the sake of clearness I will present some code pieces out of context. If you want to see them in context, you can download the code.
Since the Select-part is easier, let's focus on it first. The grammar looks like this:
Expr := <VariableDescription>[, <VariableDescription>, ...]
VariableDescription := <name> [as <alias>]
name is a column name, and alias can be chosen freely. So lets see how we can parse such an expression.
class Select:
Var = namedtuple("Var", ["name", "alias"], defaults=(None,))
@staticmethod
def _to_var(expression: str):
return Select.Var(*expression.strip().split(" as "))
def __init__(self, instruction: str):
self.vars = tuple(map(Select._to_var, instruction.split(",")))
First, in the __init__() method, the string is split at the commas, and
the remaining parts should be
either a column name or a substitution like "kappa as value". These strings
are mapped through the _to_var() method. Var is a namedtuple that just
stores the name and a possible substitution, which has a default value of
None, so it can be created by Var(name, substitution) or just Var(name).
Splitting "kappa as value" at " as " results in ["kappa", "value"] and
splitting "kappa" at " as " results in ["kappa"]. The resulting list can, in
any case, be used as arguments for Var using the asterisk. So for the string:
"subscript, kappa as value" self.vars will be
[Var("subscript"), Var("kappa", "value")]. In order to be able to use
Select(expression)(dataframe) the object needs a __call__ method. Completed
it looks like this:
class Select:
Var = namedtuple("Var", ["name", "alias"], defaults=(None,))
@staticmethod
def _to_var(expression: str):
return Select.Var(*expression.strip().split(" as "))
def __init__(self, instruction: str):
self.vars = tuple(map(Select._to_var, instruction.split(",")))
def __call__(self, df: pd.DataFrame)-> pd.DataFrame:
selected_frame = df[[var.name for var in self.vars]]
return selected_frame.rename(columns={
var.name: var.alias
for var in self.vars if var.alias
})
in the __call__ method we use the Var.name attribute of all stored vars to
select the columns from the DataFrame that is passed as parameter, and then
rename those columns, for which we have an alias.
The Where statement will work in a similar fashion, and we add a Where
method to be able to do something like
Select(expr).Where(filter_expr)(dataframe)
class Select:
...
def Where(self, expr: str)-> Callable[[pd.DataFrame], pd.DataFrame]:
where_filter = Where(expr)
def inner_func(df: pd.DataFrame)-> pd.DataFrame:
return self(where_filter(df))
return inner_func
It simply creates a Where filter object and returns a function that applies
the filter and then passes the results to its own __call__ method.
So lets look at the Where class, which is way more exciting.
The Where object must take a string like "col1 > 5 and col2 == 'value'" and
filter a DataFrame accordingly. We could try fiddling around with string
splits, but handling all possible operators for all the possible data types
will be hard. Python can already handle this kind of strings, there are
functions like eval and exec. But we need to change the interpretation of
the expression slightly. We want to change the and to a & and the or to a
|, also we need to change col1 to my_frame.col1. This can be done using
abstract syntax trees (AST).
But what is an AST? The easiest method to explain is an example. The following
AST belongs to the expression: "col1 > 5 and col2 == 'value'":
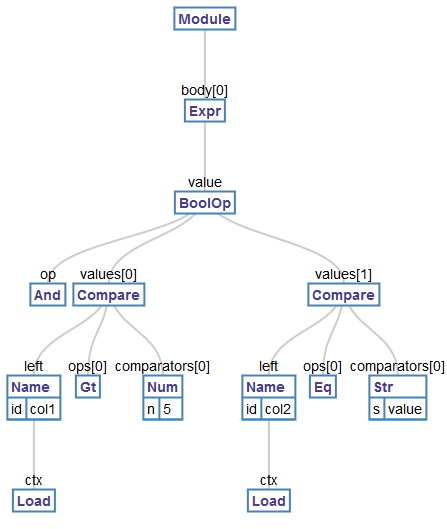
(BTW: this image was created using the Python AST Visualizer)
This looks scary on first sight, but it's really not that bad. Forget about the
Module and the Expr nodes, those don't matter here. It starts to get interesting
at the BoolOp node. This node represents the complete (boolean) expression
above. At the upmost level it consists of an and statement, which has two
values, both of which are comparisons (the Compare nodes).
The left comparison has the operation
"greater than" encoded as Gt, the left value is "col1" which is a node of type
Name with the id "col1" and the context (ctx) Load (possible contexts are
Load, when a variable is accessed, Store, when a value is assigned, and
Del, when it's deleted). "Col1" is compared to 5, which is the first
comparator. If we had used something like "1 < col1 < 10" the left value would
be one, and there would be two comparators, "col1" and 10. The other compare
node works the same. We will now manipulate the tree, and replace the BoolOp
with BinOps. A BoolOp can have multiple values that are compared, a BinOp
can only compare two values. Therefore it is necessary to replace the single
BoolOp with nested BinOps like this:
A and B and C and D
->
A & (B & (C & D))
The other thing we need to change is to transform "col1" to "dataframe.col1".
For this, we need to exchange the Name nodes with an Attribute node, which
is used to get an attribute from an object. To do this we need to know the name
of the object that has the attribute in the scope in which the tree is
evaluated. That is easy though. It is the name of the parameter of
Where.__call__. So let's look at the necessary code. First we need to create
an AST based on an expression
class Where:
def __init__(self, expr: str):
filtered_tree = Where.TreeRewriter("df").visit(ast.parse(expr))
expression = ast.Expression(body=filtered_tree.body[0].value)
ast.fix_missing_locations(expression)
self.compiled_expr = compile(expression, filename="<ast>", mode="eval")
ast.parse will create the tree from a string. Then the tree will rewritten. The
"df" is the name, that the DataFrame will have in the evaluation context. Then
the result is wrapped into an Expression which is necessary to be able to use
it in combination with eval instead of exec. Subsequently we call
ast.fix_missing_locations(). This is because we will have inserted new nodes
that didn't exist in the original tree. Every node needs to have a line and a
column referenced to be able to know from which place in the source code it
originated. Our newly created nodes won't have valid values for these attributes,
and ast.fix_missing_locations() will fill them in for us. Then we call
compile on the tree. Additionally we pass the
information, that we want to evaluate the expression instead of executing it
(which basically means that we want a value back),
and a filename from which the tree was generated. Since we don't have a file, we
simply pass "\<ast>" it could be anything though. We then store away the
compiled expression for later use.
So let's see how we can actually rewrite this tree. To do this we need a
visitor class. This class must have one method for every node type we want to
manipulate, in our case Name and BoolOp. The methods must be named
"visit_ast.NodeTransformer.
These methods must then
return the node that should replace the node that was provided as argument.
class TreeRewriter(ast.NodeTransformer):
def __init__(self, mat_name):
super().__init__()
self.mat_name = mat_name
# some stuff is missing here ...
def visit_Name(self, node):
return ast.copy_location(ast.Attribute(
value=ast.Name(id=self.mat_name, ctx=ast.Load()),
attr=node.id, ctx=ast.Load()), node)
def visit_BoolOp(self, node):
self.generic_visit(node)
return ast.copy_location(self._nested_bin_op(
Select.TreeRewriter._bool_op_replacement_type(node),
node.values), node)
The visit_Name() method is straight forward: it returns an ast.Attribute with a
new value, which is the DataFrame, that will be passed to Where.__call__,
and the attribute (attr) will be the id of the Name node, e.g. "col1".
Additionally we use ast.copy_location to copy the location information from
the old node to the new one.
The next method, visit_BoolOp() is a little more complex. Since the node has
children, that won't be visited when we replace it, we have to call
self.generic_visit() on it first. self.generic_visit() is inherited from
ast.NodeTransformer. Then we find the type for the new BinOp via
Select.TreeRewriter._bool_op_replacement_type(), which is defined as follows:
@staticmethod
def _bool_op_replacement_type(node):
return ast.BitAnd if isinstance(node.op, ast.And)\
else ast.BitOr
and then create the nested BinOps with self._nested_bin_op() from the
replacement type and the values of the provided BoolOp.
def _nested_bin_op(self, bop, values):
bot_most = ast.BinOp(left=values[-1],
right=values[-2],
op=bop())
current_top = bot_most
for node in reversed(values[:-2]):
current_top = ast.BinOp(right=node,
left=current_top,
op=bop)
return current_top
we start constructing the subtree from the bottom. So for the example
a and b and c and d we first create c & d from there b & (c & d) and then
a & (b & (c & d)).
Now, all that is missing is the application of the compiled tree which happens in
the Where.__call__() method:
def __call__(self, df: pd.DataFrame)-> pd.DataFrame:
filter_obj = eval(self.compiled_expr)
return df[filter_obj]
Again, you can download the complete code here. Also if you want to find out more about the AST, or use it in your own projects, I recommend this tutorial.
Using the code presented here is slightly slower than using pandas directly. So
I would not recommend to use a Select or a Where inside a loop that is
repeated thousands or millions of times.